

地址: 上海市静安区共和新路4718弄10号楼2楼
热线:400-166-3538
电话:13122077371
邮箱:sales@shyuanzhen.cn
1.反斜杠的插入
还是以Disallow:/a/b.html为例,在编写该语句的时候,如果忘记加入了反斜杠,则是对全部内容进行开放,这与编写语句的想法相悖,因为反斜杠的意义是根目录。
2.空格的出现
空格的出现就很好理解了,因为搜索引擎对于这个特殊符号的出现并不识别,它的加入只会使语句失去应有的效用。
第二:编写的几个问题
1.Robots.txt编写的顺序问题
举个最简单的例子,如果你想让自己a文件中的b.html被抓取,那么你怎么编写呢?是Allow:/a/b.html Disallow:/a/ 还是Disallow:/a/ Allow:/a/b.html这样?
在Robots.txt编写规则中,它并不执行树状分析结构,换句话说编写时并不应该把母文件夹放在最前,而是遵循一种就近原则,如果我们把母文件夹放在前面,蜘蛛会认为这个途径被封闭了,不能访问,而我们最终的目的却是访问,这样一来,目标和实际就大相迳庭了。
2.Robots.txt编写的开放性问题
很多上海网站建设 的站长,尤其是新手站长对于Robots.txt的理解过于片面,他们认为既然Robots.txt可以规定蜘蛛的访问途径,那我们何必不开放,把所有文件都设置成可访问,这样一来网站的收录量不久立即上升了,其实问题远远没有我们想象的简单,大家都知道网站中一些固定的文件是不必传送给搜索引擎访问的,如果我们把网站“全方位开放”,后果就是加大网站服务器负载,降低访问速度,减缓蜘蛛的爬行率,对于网站收录没有一点用处,所以对于固定不需要访问的文件,我们直接Disallow掉就可以了。
一般情况下,网站不需要访问的文件有后台管理文件、程序脚本、附件、数据库文件、等等。
3.Robots.txt编写的重复性问题
我们每天都在写着原创内容,然后更新到自己的网站中,大家想过没有我们这样做的目的是什么?当然是为了讨搜索引擎的好,大家都知道搜索引擎很看重原创内容,对于原创内容的收录很快,相反,如果你的网站中充斥着大量的复制内容,那么我只能遗憾的告诉你,网站的前途一片渺茫。不过这也从另一个方面告诉我们要积极的利用robots文件禁止重复页面的代码,降低页面的重复度,但是在编写robots文件时一定要记得
在User-agent后加入某个搜索引擎,例如User-agent:BaiduSpider Disallow:/,如果没有加入,编写成User-agent: * Disallow: /形式,则是对网站所有内容的“屏蔽”。
4.Robots.txt编写的meta问题
在 Robots.txt编写规则中,有一个取最强参数法则,而且如果网站以及页面标签上同时出现robots.txt文件和meta标签,那么搜索引擎就会服从两个规则中较为严格的一个,即禁止搜索引擎对于某个页面的索引,当然如果robots.txt文件和meta标签不是出现一个文件中,那么搜索引擎就会遵循就近原则,就会索引meta标签前的所有文件。
电商平台营销成本越来越高,私域流量成为商家降本增效的必然路径,但是从电商如何引流到微信,以及在微信内如何高效运营用户是现阶段不少商家的一个经营痛点。
在本篇文章中您将看到:
1、淘宝商家如何构建私域流量?
2、在私域用户运营中如何维持高复购和忠诚度?
3、维系客户信任关系的关键元素。
4、打造新品牌的有效路径。
本文约 4400 字
阅读大约需 7 分钟
")
微信号不多,总共只有 4 个,用户好友总数量也不多,累计 4000 多人,创始团队没有营销背景,运营甚至有点佛系,但这款植物精油美护品牌的产品复购率却达到80%,年销售数百万,同时入选了吴晓波频道·百匠大集。
芳研社的创始人清芬和Leona ,分别是新加坡生物学博士和留德化学硕士,出于对精油和芳疗的热爱共同走上了芳香事业。后来他们俩另外一个好朋友小珂也加入进来,现在清芬和Leona主要负责实验室产品研发和运营,而小珂主要负责视觉设计和直播分享,三个好闺蜜在芳香事业上正在稳步前进。本期私域运营指南(ID:newrankco)专访芳研社创始人清芬博士,了解这一精油美护品牌运营私域流量的方法论。
芳研社目前在淘宝平台上的旗舰店评分是4.9。“不关注精油圈的人可能会觉得芳研社是一个小众品牌,但是在精油圈内芳研社的口碑是很好的。”芳研社创始人清芬在访谈时说。
清芬在博士刚毕业时,也在淘宝代理过其他国外品牌的精油产品,在慢慢积累了一些选品和采购经验后,于 2014 年注册了公司以及芳研社商标,推出自己的精油护肤与洗护发产品。
2019 年,受公域平台营销成本以及行业理念的影响,芳研社也开始全面整合私域流量。据清芬说,她们的方法是“主动去添加在店内已购客户的微信”,因此,芳研社的 4000 多个私域用户目前来源主要是淘宝平台。这些微信好友用户的价值很高,“现在大家的时间都很宝贵,通过芳研社好友申请的客户都是对产品和品牌认可的用户。”清芬说。
而在私域用户运营方面,芳研社也逐渐摸索出了适合自身的一条有效路径,使产品的复购率能够高达80%,年营业额数百万。具体来说,主要着力点是在产品打造、用户运营、坚守自我以及每个环节的专注专业上。
1
产品是根本
最好的原料+不断创新
清芬表示,芳研社今天在用户中能够有一个良好口碑,首先最重要的还是产品本身。团队对单方精油和原料的把控非常严格,也会去原产地考察,比如店内一款非常经典的蓝莲香调就是团队亲自去印度找回来的精油。
目前芳研社的产品SKU有几十款,类别主要包括洗护发、面部护理和芳疗精油。“虽然产品SKU不多,但每一样从原料选择、精油调配到配方整合,都是非常用心,过去三年有一半以上的精力都花在研发产品上。”
在产品研发过程中,芳研社会引导用户深度参与。芳研社有自己的“天使用户群”,群友主要由老顾客、老粉丝构成。每当研发新品时,芳研社都会从产品提案、气味、成分偏好,甚至包装和名字等多个环节主动征求芳友们的意见,让她们试用和投票,再不断改进直到用户满意。
“这样产品面世就有芳友的参与在里面,她们开心,同时对新品也有一个预热的过程。”清芬说。
产品的持续创新也至关重要。清芬表示,无论如何有一点不能变,就是芳研社要保证产品理念始终最新,能引领别人。“哪怕我们不会卖,只要能保证我们的理念永远都是最新的,那就一定会有客户追随我们。”
因此团队始终不断更新原料,也在不断寻找新的稀缺性精油。另外,清芬接触和练习正念( 一种系统的心理疗法)多年,从中受益颇多,近两年想到可以把正念引入护肤领域。她以此为例解释,“当别人还在拼价格的时候,我们走到了正念护肤,这就领先了别人很多,那就会有人愿意买单。”
2
私域用户运营
知识分享+情感交流
由于芳研社长期坚持和用户之间进行知识分享以及情感交流,芳研社在微信内的 4000 多名私域用户忠诚度很高。而无论是朋友圈、社群、公众号和淘宝直播的运营,还是一些细节,都在贯彻这一理念。
为了让品牌的调性保持一致,芳研社格外注意对外的形象打造。比如,除去清芬本人的微信外,另外 4 个客服微信的名字“草暖、蓝莲、雪松、甜橙“均源于精油。平时,客服在朋友圈会有规律地发布内容,包括三分之一芳疗和护肤知识,三分之一的生活美学,还有三分之一的活动通告、创始人日常、直播与微课预报、芳友返图等等。当然,芳研社的客服也会积极对用户的朋友圈进行点赞和评论。
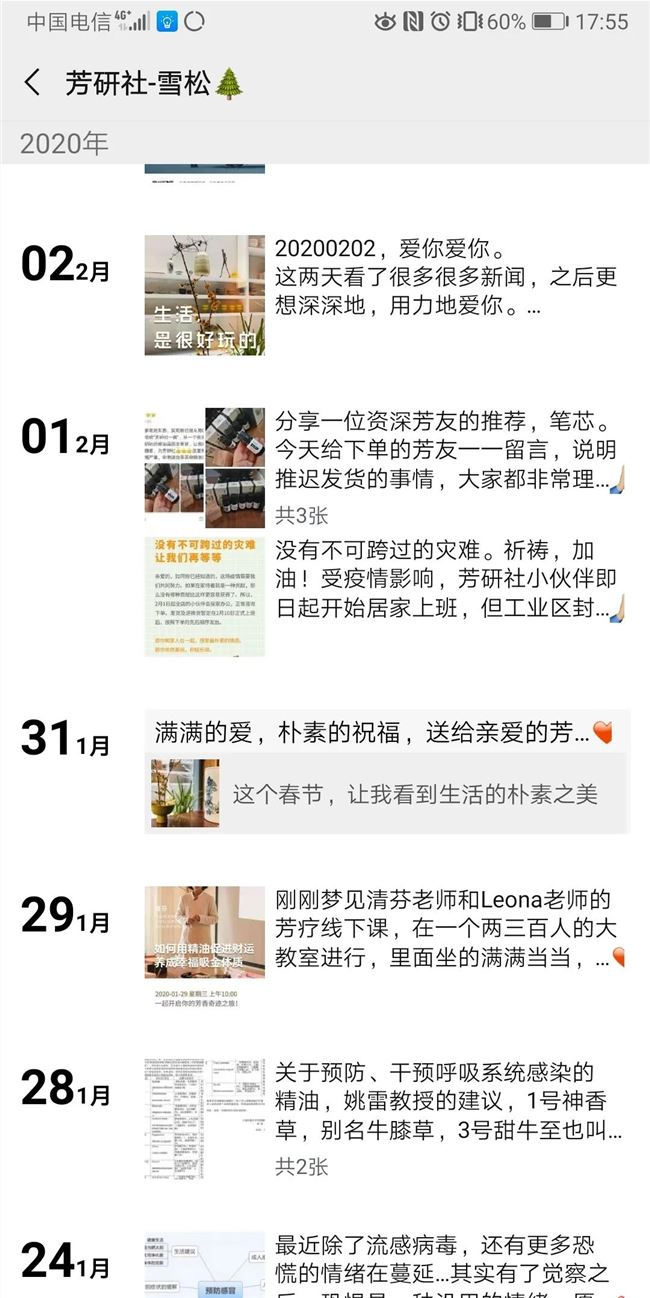

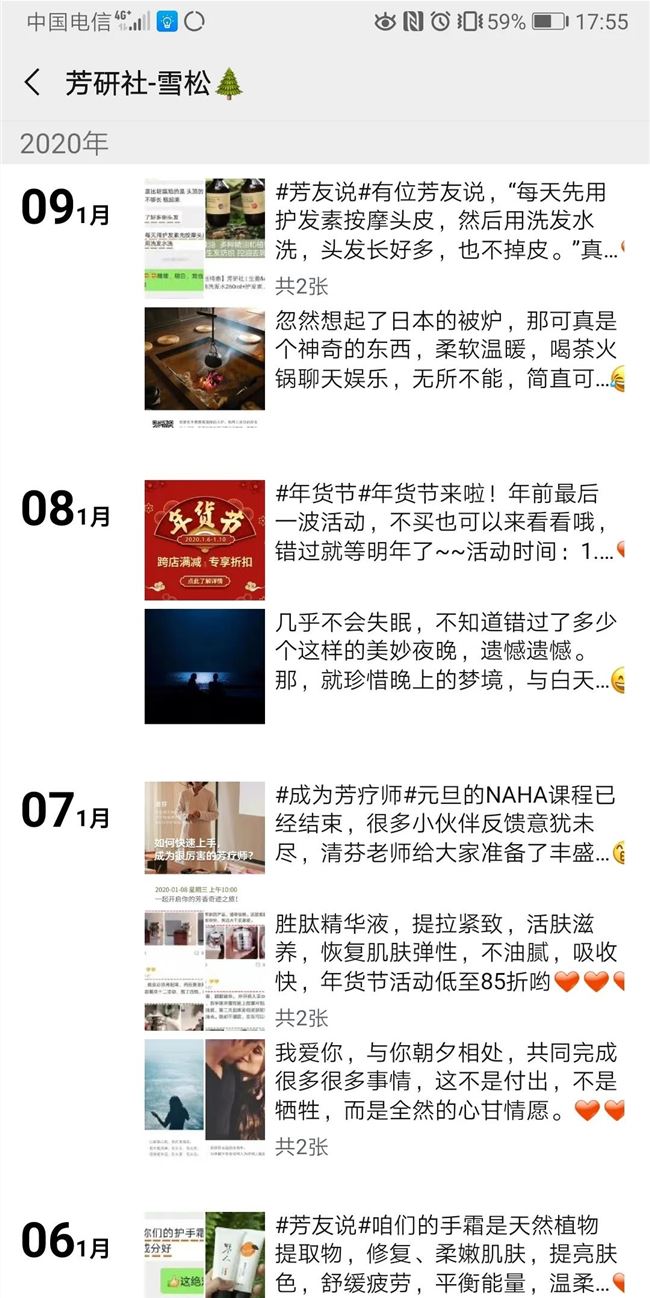

(芳研社的朋友圈)
老顾客会对朋友圈频繁出现的知识简报和文艺海报比较熟悉。其中知识简报是客服根据清芬平日的讲课内容摘取编辑的关于芳疗护肤的知识,用于持续性地向用户科普芳疗。
而后者则是团队设计师每天设计出的一张海报,配有文艺语句。“这个持续的内容板块吸引了很多人“,清芬说,“很多用户会自动转发海报到朋友圈,因为感觉说的话戳中了内心”。带有二维码的海报也助力了芳研社的传播。
团队每周进行复盘,根据朋友圈内容的点赞评论不断优化。清芬认为朋友圈运营的关键词是“原创”,坚持原创让客户感受到品牌背后鲜活的生命力,从而愿意持续关注。
在社群运营方面,芳研社根据主题划分社群,包括护肤、护发、上新与优惠群等,以及上述提到的参与产品策划、试用,由多年忠实粉丝组成的天使群。
在社群内,除了日常围绕芳疗洗护进行话题讨论及售后交流外,固定活动是每周一次的线上社群微课分享。微课以精油为核心,涵盖护肤、护发、芳疗、育儿、生活美学等女性相关的方方面面。例如,《芳研社的正念护肤课》、《芳研社的NAHA精油课》等。这部分课程主要由清芬研发和打磨,内容方向主要是根据用户需求以及清芬个人的兴趣和学习研究进度而定。最近清芬也开始尝试在社群内分享日志,与芳友们分享生活中的点滴。而Leona除了负责线下课程外,也在研发《芳香心理学》、《精油化学》等部分线上课。
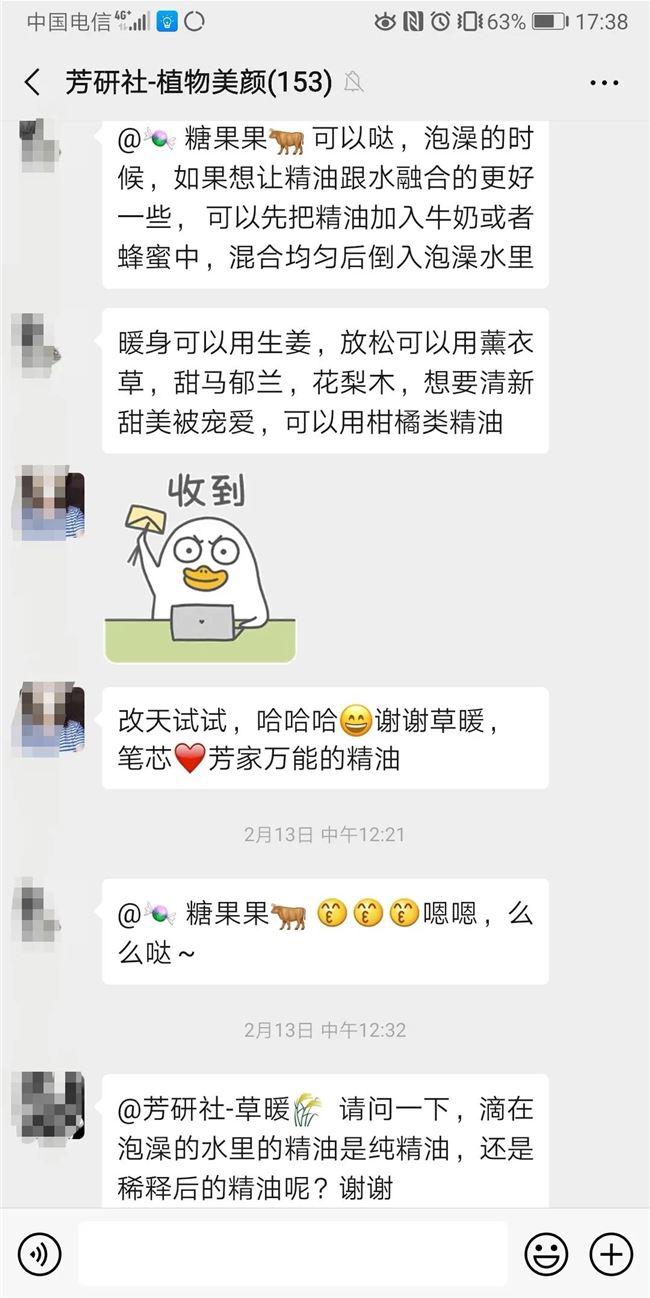
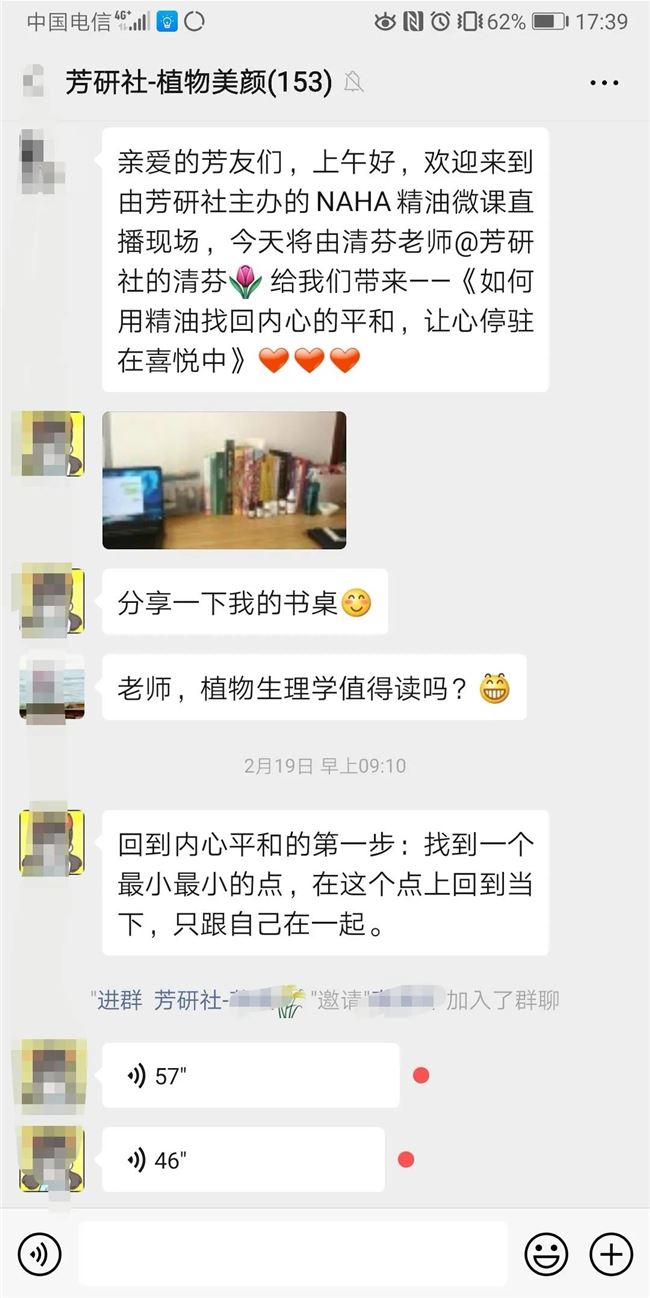
(芳研社的社群)
在专业指导方面, 2018 年Leona尝试过一个护肤私教群,手把手带领一群小伙伴每天打卡,真正深入解决她们的护肤问题,去挖掘学员有哪些痛点。今年芳研社打算创新升级形式,打造正念护肤训练营,让学员把正念和护肤结合起来,加深对自身皮肤的理解,从而更高效地解决护肤问题。
公众号方面,芳研社的服务号内容除了产品上新,活动预告之外,有两点让私域运营指南(ID:newrankco)印象深刻,一是三位合伙人对自己生活状态和感受的记录占相当篇幅,受到读者喜爱。清芬说这是“做自己”的一种延伸,类似于向用户吐露心声。这类内容也经常会渗透到活动推送中,使其不会显得很生硬。
除了平日里用心体验、积累真实感受之外,清芬团队也在文字方面下过功夫, 2016 年这个账号还是订阅号,“以每天一篇原创的要求专门训练过文笔”。不仅“把写的功夫练出来了”,也由于每天都需要查阅大量精油资料,在专业知识层面不断积累精进。
账号内容另一特点是经常和读者互动,并且多是生活性问题。清芬表示,这是为了和用户增进情感交流。“该谈产品时专注谈产品,要严谨。但是该谈感情时就专注情感交流。”实际上,这种情感表达还有多种形式,清芬经常会在将要邮寄给顾客的包裹中放入她亲自手写并打印的纸质书信,向顾客传达她想说的话。

(清芬的手写信)
除了朋友圈和社群运营,芳研社也紧跟市场风向,每周都有淘宝直播分享,团队的另外一个合伙人小珂由于“有亲和力、兴趣广泛、喜欢跟人交往”,负责每周三次的直播。和当下近乎“疯狂”的直播带货不同,小珂直播的地方就在她家厨房或饭厅,往往是一边喝茶一边聊天,分享一本书、一本电影,分享她的手工或者瓷器,也分享她对精油的感悟和护肤心得。
清芬说,小珂的角色就像一个桥梁,她和Leona的工作主要是在实验室里,客户是在市场上,彼此之间是有距离的,而小珂在直播里呈现了一个生活中很真实的状态,让客户感受到诚恳和温暖,消弭了品牌与受众之间的距离感。
专业知识分享让用户在产品方面用的放心,而“日常的情感交流则让用户在这里仿佛找到了一个心灵港湾”,清芬表示,芳研社总的原则是保持学习和进步,不断给老客户带来新鲜感,不断去增加彼此的信任。
3
坚持做自己
坚守真实,成为光源
清芬在采访中多次提到“做自己”。她认为做产品、运营朋友圈、与客户沟通互动,这些都是“做自己”的延伸,当对自己的初心从一而终时,顾客也会从一而终地对待你的品牌和产品。“客服问我某个问题该怎么和顾客沟通时,我就说三个字,讲真话。”
一方面她觉得“做自己”是最轻松的,另一方面,她认为这也是芳研社顾客忠诚度高的原因。
在被问及对私域流量的看法时,清芬认为经营私域流量有一条暗线,一条明线。暗线是个人IP的成长进化,只有自己不停进步,才能持久吸引粉丝。明线是内容产生,加微信、拉群、活动策划、日常运营这些,可以根据原有的人员配置情况建立标准流程,有规律的运营让粉丝有安全感,愿意一起玩下去。
清芬希望把精力放自己身上,让自己能够扮演一个光源的角色。“当一个人心态从容,做事严谨,生活也很精彩时,其他很多人就会也向往这种状态,就会信任Ta做出来的产品。”
在这种理念下,芳研社在运营的某些层面甚至显得有些佛系。比如没有去其他各种公域平台引流,邀请用户进群绝对尊重其意见,绝不私信打扰用户,也不太注重每次活动中的裂变和推广。甚至在转化环节,接纳某些顾客的不喜欢,不迎合,不讨好,只是做自己。”
“我就只做自己喜欢的,做自己想要的,当用户跟我同频共振的时候,她就会觉得这也是她想要的。因为我特别诚实,只说真话,所见即所得,当我们坚持这样的态度,客户就会有极大的安全感。现在社会很多生意都求快,就会造成信任缺失,但在我们这里不存在这个问题,很多客户他们会来来回回的,就是她走了,我们也没觉得有什么关系,过段时间发现她又回来了。”
比起同行,清芬认为芳研社的产品有三大核心壁垒,一是“行业很多人是把这个事完全当生意来做,而我们更多是当做专业来做”,学术出身的她表示目前她们来做的应用研发实际上是一种降维打击。其次芳疗产品需要一定知识背景才能上手使用,其他公司要么有产品没课程,要么有课程没产品,但“我们既有产品又有课程,能带领大家使用”。此外清芬也表示,她们是自家产品的资深用户,既是产品经理又是用户,而“在护肤品的品牌里面,很多人都不用自家产品。”
一个案例可以展示芳研社在产品研发方面的某些理念。 2015 年团队研发一款洗发水,为了测量头发生长速度,清芬甚至剃了光头来实验。后来这个故事被有赞挖掘到,用公号推送相关产品, 3000 套生姜&雪松精油洗护发产品 4 小时售罄,当晚销售额突破 20 万元。实际上,这种亲身试验的理念一直都存在于芳研社的实验室中。
写在最后
正念中有个理念是关注当下,“念念分明”,清芬主张把这个理念应用到做事中,认为做产品的时候就要一心做产品,分享知识的时候就一心分享知识,不要同时想着金钱回馈,然后交流感情的时候就单纯的谈感情,这样自己会比较轻松,客户感受也会好。“当你念头不纯粹的时候,其实大家是能感受到的。”
关于如何打造新品牌,她觉得好看的皮囊和有趣的灵魂缺一不可。“Leona和我基于对芳香疗法的热爱创立了芳研社,我们俩在芳疗方面十年如一日的专注给芳研社品牌注入稳定的灵魂,而 2018 年小珂的加入又给品牌带来好看的皮囊”。
之所以在私域用户运营方面做出成绩,她表示“对商业我们是不太在行的,走到今天完全靠团队所有小伙伴的专业敬业、对护肤和芳疗的热爱、对个人成长的持续精进。
• • • • | 公司名称:上海缘震网络科技有限公司 开户银行:中国工商银行上海市彭浦支行 银行账号:1001 2508 0930 0206 455 |
总部:上海市奉贤区金海公路6055号29号3楼 分部:上海市静安区共和新路4718弄10号楼2楼 商务官网:www.shyuanzhen.cn 彦蓁科技:www.shyanzhen.cn | 缘震网络成立于 2014 年,公司主要经营全案策划,高端品质网站建设、多媒体视频宣传片制作、微信公众号开发、微信小程序开发、商城定制、SEO优化、电商托管、空间托管、网站维护、应用软件开发、手机端APP开发、等为客户提供一条龙网络运营解决方案的的技术型企业。我们在人力资源、业务范围、设计、技术、服务、信誉度、规范管理及企业文化等诸多方面完善自己,公司目前已与千余家各类客户进行长期战略合作,提供专业的网站建设与运营服务。我们的口号:广结良缘、震古烁今! |















 免费热线:400-166-3538
免费热线:400-166-3538






